
우선, Semantic Segmentation에 대해 알아보기 이전에, Computer Vision의 대표적 Task 2가지인 Object Detection 과 Image Segmentation 의 차이에 대해 알고있어야 합니다.

해당 그림을 보면, Object Detection은 여러 객체(Multiple Objects)를 감싸는 Bounding Box(테두리 박스)를 각각 만드는 Localization을 수행하고, 이 Bounding Box가 가지는 객체(class)가 무엇인지에 대해 Classification 을 수행합니다.
반면 Segmentation은 Bounding Box(테두리 박스)없이 객체의 포토샵 누끼를 따듯 경계선을 정확히 분할합니다. 위의 사진에서는 Instance Segmentation으로 언급되어 있지만, 정확히는 Semantic Segmentation입니다.

Instance Segmentation은 위의 우측 사진처럼 단순히 객체만 분류하는 것이 아니라, 같은 객체여도 서로 다른 instance 를 분류해주는 점이 Semantic Segmentation과 차이가 있습니다. 그렇기 때문에 Instance segmentation과 Semantic Segmentation은 명확하게는 다른 용어입니다. 추후에는 Semantic Segmentation만 다룰 예정이므로 이 부분에 대해 이해가 안되셨어도 넘어가시면 됩니다.
Semantic Segmantation이란?

딥러닝 기반 Semantic Segmentation 은 기존 라이다나 센서 기반이었던 자율주행의 판도를 바꿀 정도로 빠르게 발전하고 있습니다. 자율주행 뿐만아니라 사진 촬영시 사물제외 배경 블러 처리, Crack 탐지를 통한 노후도 측정, 세포 구분(U-Net) 등과 같은 다양한 Task에서 사용됩니다.
Semantic Segmentation은 해당 영상(Image)의 모든 픽셀 각각의 class를 Classification하는 Task입니다.

Input Image(RGB-색상 3차원(3chanel) 또는 흑백(1 chanel)를 받아 처리를 하는 과정은 논문별로 다르겠지만, Output이 Pixel 별로 Class Label을 가지는 것은 같습니다.

다만, 모델을 학습시키기 위해서는 Ground Truth라는 픽셀별로 라벨링된 정답 라벨이 있어야 합니다. Custom data에 라벨링을 하는 경우 다양한 툴을 사용해야 합니다. 가장 많이 알고 계시는 포토샵을 사용하기도 하고 따로 Segmentation Tool을 사용하기도 합니다.
Semantic Segmentaion 평가 요소
Semantic Segmentation의 평가요소는 크게 두 가지로 구분해볼 수 있습니다. 바로 성능 측면과, 속도 측면입니다. 자율주행과 같은 실시간 적용이 필요한 Task의 경우엔 아무리 성능이 좋아도 시간이 너무 오래걸리게 되면 사용이 불가하기 때문입니다. (+자율주행과 같은 실시간(real-time) Task에 사용하려면 Fps 기준 최소 30 이상은 나와야 한다고 합니다)
1) 성능
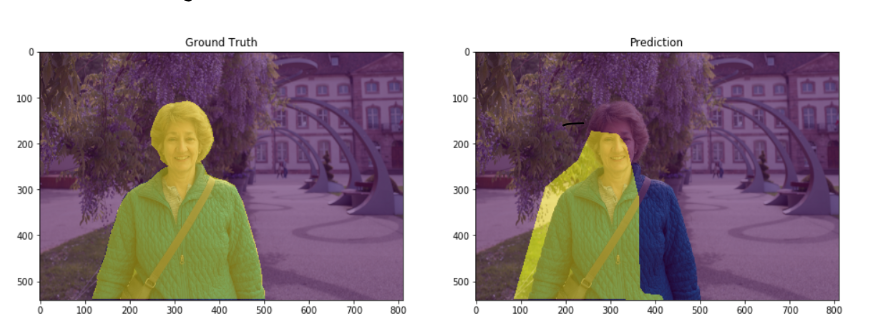
그럼, 사람에 대한 Class만 예측한다고 가정할 때 정답 라벨이 왼쪽과 같고, 모델이 예측한 라벨이 오른쪽과 같은 경우에 성능에 관련한 지표를 어떻게 평가하는지 확인해보면, 평소 많이 사용하는 confusion matrix로 생각해보면 다음과 같이 구분할 수 있다.


모델이 예측한 부분이 Class에 해당하는 부분은 TP(True Positive),
모델이 예측하지 않은 부분 중 Class에 해당하지 않는 부분은 TN(True Negative),
모델이 예측한 부분이 Class에 해당하지 않는 부분은 FP(False Positive),
모델이 예측하지 않은 부분이 Class에 해당하는 부분은 FN(False Negative) 이다.
- IOU(Intersection over Union)
IOU를 쉽게 설명하자면

이다. 즉, 분자는 모델이 정답을 맞춘 부분이고, 분모는 정답 + 모델이 예측한 부분(잘못 예측한 부분도 함께) 이다.
이를 confusion matrix 요소로도 표현해보면

와 같다.
- Pixel Accuracy
Pixel Accuracy 는 말 그대로 전체 정답 라벨 중에 모델이 정답 Class 를 맞춘 부분이다.

기본적인 개념은 같으나 이를 Class별, 픽셀별 등으로 나누어서 사용하기도 한다.

이외에도 f1-score 등도 사용하기도 한다.
2) 속도
- Fps(Frames Per Second)
1초당 몇 프레임을 처리할 수 있는지를 말한다. 실시간(real-time) 사용 가능하려면 최소 30 fps 의 성능이 나와야 한다.
- GFLOPs(Giga FLoating point Operations Per Second)
초당 부동소수점 연산이란 의미로 1초동안 수행할 수 있는 부동소수점 연산의 횟수를 기준으로 삼음.
자세한 내용은 위키 페이지(https://ko.wikipedia.org/wiki/%ED%94%8C%EB%A1%AD%EC%8A%A4) 참조
- Time 단위(ms etc.)
밀리세컨드(millisecond)를 기준으로 많이 사용함. 프로그램 수행 시간을 측정할 때 초를 대신하는 시간의 단위로 활용한다.
Semantic Segmentaion 구성요소
Segmentation 은 기존 Object Detection 의 VGG, ResNet 등 처럼 수많은 Layer를 사용한다고 성능이 좋게 나오지 않습니다. 왜냐하면, 여러 Layer를 거치게 될 수록 Max, Average Pooling이나 특히 FC(Fully Connected) 과 같은 변형이 발생하게 되면 픽셀의 위치 정보가 손실되기 때문이다. 그렇기 때문에 Segmentation은 FC(Fully Connected) 사용을 지양한다. 대부분의 Sota Segmentation 모델에도 FC(Fully Connected) 레이어가 잘 포함되어 있지 않다.
공간정보를 위해 Max, Average Pooling이나 특히 FC(Fully Connected) 레이어를 모두 삭제하고 Stride 1과 같은 Convolution Layer 만을 사용할 수도 있지만, Parameter 수가 너무 많아 효율이 떨어진다. 이렇게 구성한 모델은 애초에 Fps 가 30은 커녕 0에 수렴할 것이다.
Segmentation에서는 Downsampling & Upsampling 을 사용한다. Segnet논문 이후에는 Encoder, Decoder라는 이름으로도 많이 사용하는데, Encoder는 주로 Downsampling을 여러 번 하는 구조를 담고 있고 Decoder는 Upsampling 을 여러 번 수행하는 구조를 담고 있다.
- Downsampling 이란, 이미지 Input 의 차원을 줄여 적은 Memory만을 사용하여 모델을 적용할 수 있도록 하는 작업이다. Convolution 사용시에는 Stride를 최소 2이상으로 설정해 사용한다.
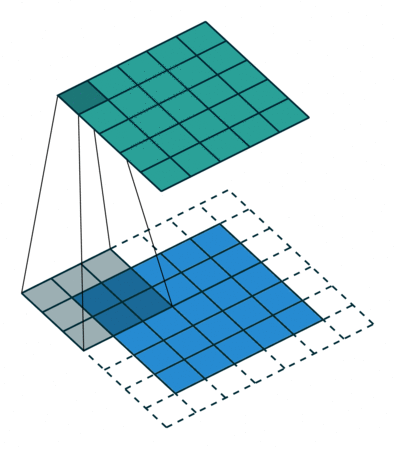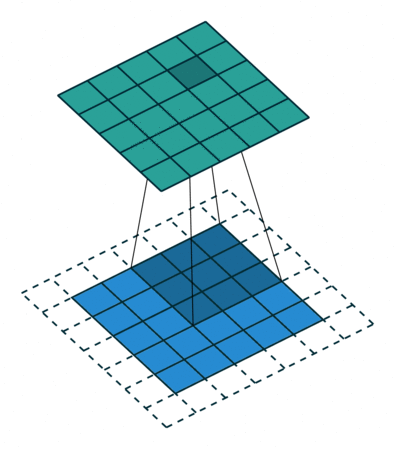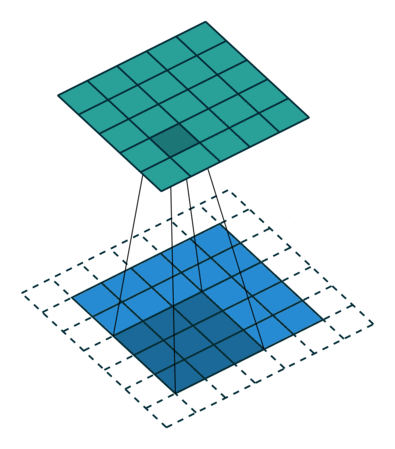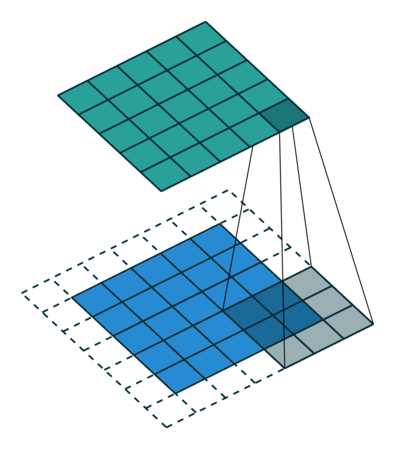
하지만 이에 대한 문제도 발생하여 Atrous Convolution(dilated convolution)같이 중간중간 건너 뛰는 Convolution 을 사용하기도 한다.

이외에도 다양한 Downsampling 방법을 사용한다.
- Upsampling 이란, Downsampling 에서 축소한만큼 다시 확대를 해서 원본 Input과 같은 차원으로 만들어주는 과정을 말한다.
Upsampling 에서도 다양한 방법을 사용하는데, 단순 Transpose Convolution, Strided Transpose Convolution 이외에도 다양한 방법을 사용한다.
이로써 기본적인 Segmentation 개념에 대해 알아보았고, 이제 추후 다룰 논문들을 통해 어떤 식으로 Segmentation 논문이 발전하고 있는지에 대하여 살펴볼 예정입니다!
1) 기본 Semantic Segmentation
2) 실시간(Real time) Task를 위한 경량화 Semantic Segmentation
3) Attention계열 Semantic Segmentation
등과 같이 나눠볼 수 있겠습니다.
reference : https://towardsdatascience.com/semantic-segmentation-with-deep-learning-a-guide-and-code-e52fc8958823
Semantic Segmentation with Deep Learning
Most people in the deep learning and computer vision communities understand what image classification is: we want our model to tell us what single object or scene is present in the image…
towardsdatascience.com
https://www.jeremyjordan.me/evaluating-image-segmentation-models/
Evaluating image segmentation models.
When evaluating a standard machine learning model, we usually classify our predictions into four categories: true positives, false positives, true negatives, and false negatives. However, for the dense prediction task of image segmentation, it's not immedi
www.jeremyjordan.me
https://medium.com/zylapp/review-of-deep-learning-algorithms-for-object-detection-c1f3d437b852
Review of Deep Learning Algorithms for Object Detection
Why object detection instead of image classification?
medium.com
https://www.jeremyjordan.me/semantic-segmentation/#dilated_convolutions
An overview of semantic image segmentation.
In this post, I'll discuss how to use convolutional neural networks for the task of semantic image segmentation. Image segmentation is a computer vision task in which we label specific regions of an image according to what's being shown. "What's in this im
www.jeremyjordan.me
'인공지능 > Segmentation' 카테고리의 다른 글
| DANet(Dual Attention Network for Scene Segmentation) 논문 리뷰 - CVPR_2019 (0) | 2021.09.03 |
|---|
Comment